

Intertext
Overview
Intertext is a tool for detecting and visualizing textual reuse. Combining machine learning methods with interactive data visualizations, it allows users to explore the dynamics of literary influence, reference, quotation, and allusion within collections of texts, and to track these dynamics over time.
Visualizing Similarity and Influence
Textual reuse raises significant social and historical questions for literary scholars. When—and why—do texts fade in and out of fashion? Which passages are most recycled, and by whom? Are particular textual features more prone to being reused? What networks of authorial influence and affiliation do these practices reveal?
Intertext offers insight into these issues through a mode of textual processing based on minhashing vectorized strings. Each work is broken down into overlapping windows of text, then further subdivided into smaller overlapping sequences of three characters each. Comparing these three-character strings in different texts produces measures of textual similarity—measures that are nuanced enough to identify not just verbatim quotation, but also more complex relationships like parody and allusion.
Users can explore these similarity measurements through Intertext’s web viewer, which is constructed from interactive React.js components. The web viewer allows users to examine results at two scales: a macro-level view across multiple texts and a micro-level deep-dive into individual texts.
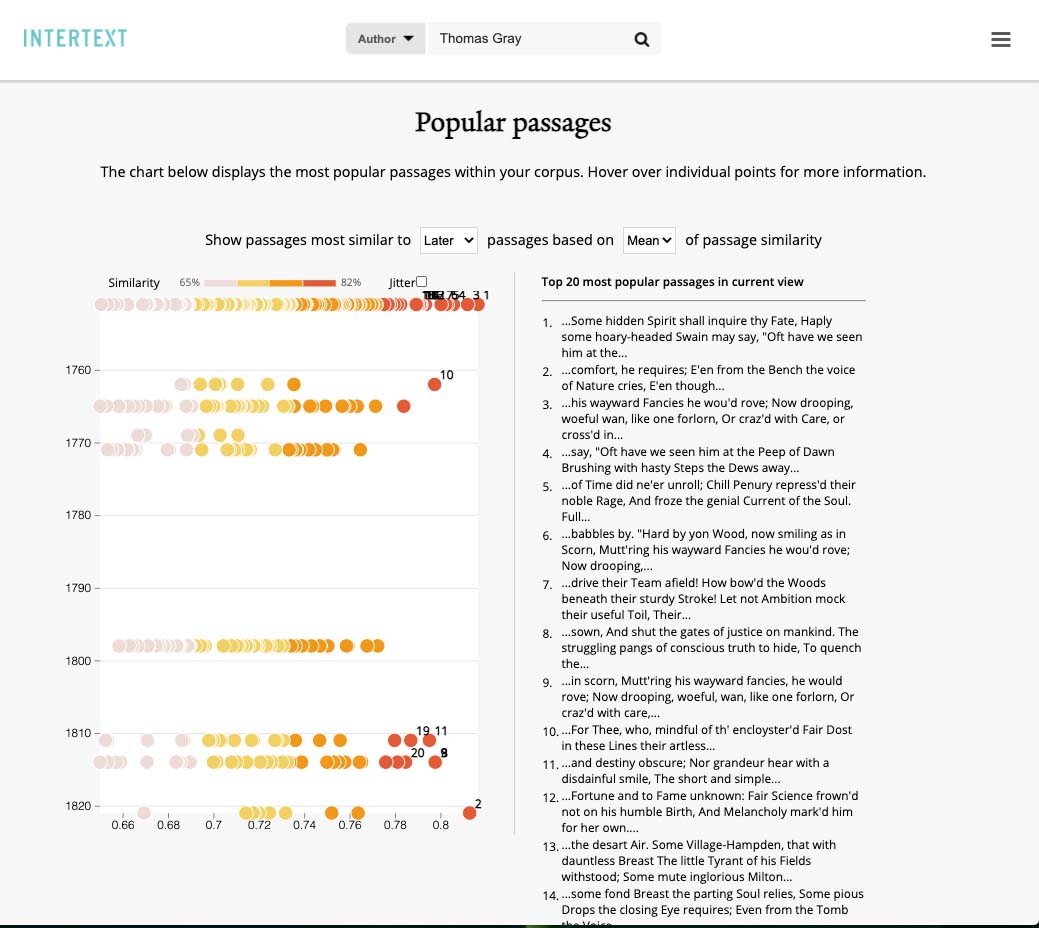 View from Intertext (version 0.1.0) of the most frequently reused passages in a collection.
View from Intertext (version 0.1.0) of the most frequently reused passages in a collection.
For a larger-scale view, users can search for a specific author or title, then peruse a list of passages that reuse text from throughout the selected work. The results can be filtered to show either previous uses (text that the author or work is reusing from other sources) or later uses (selections of the text that subsequently were reused by other authors).
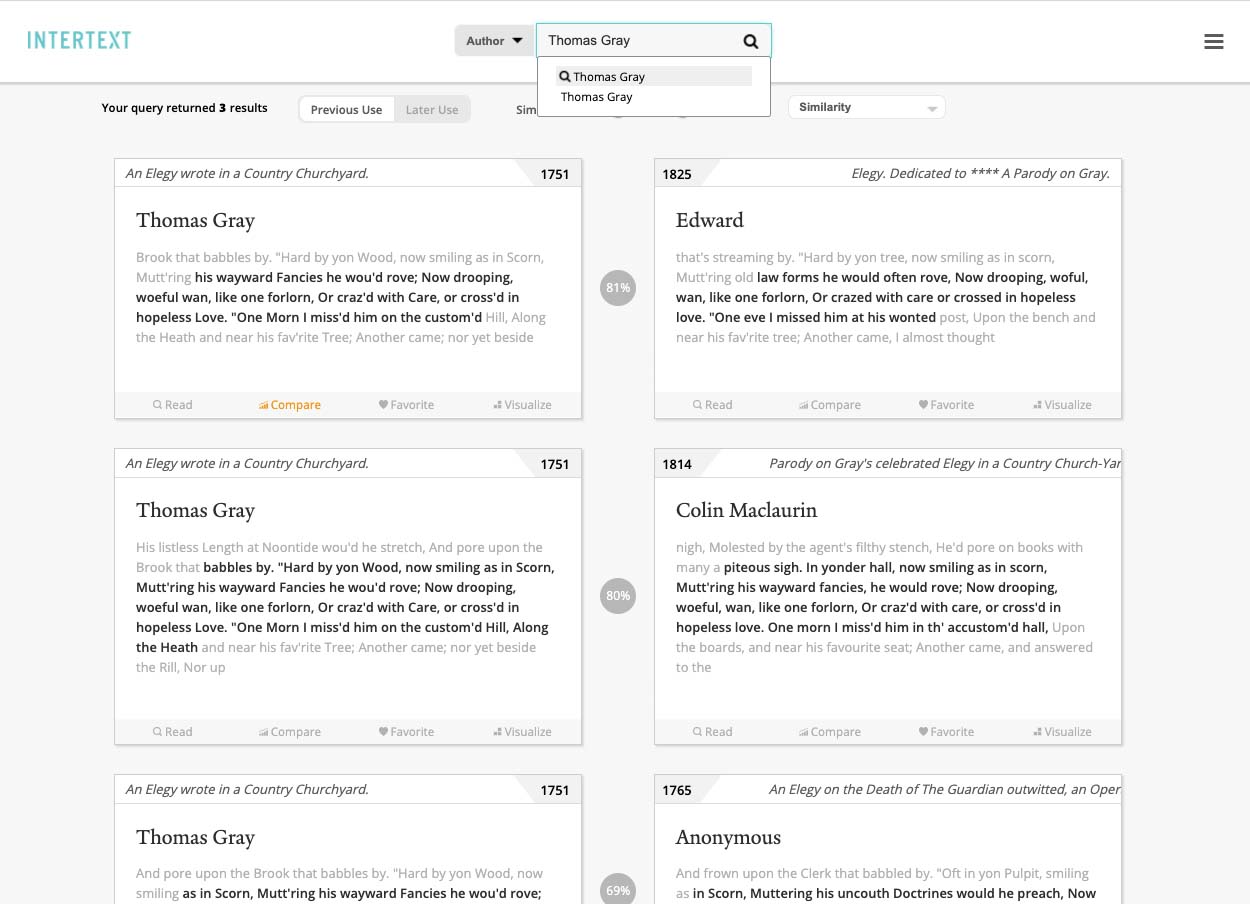 Search results for a specific author on the Intertext web viewer (version 0.1.0).
Search results for a specific author on the Intertext web viewer (version 0.1.0).
To zoom in on individual works and passages, users can experiment with Intertext’s “Compare” function, which tracks all instances of one specific passage in a corpus.
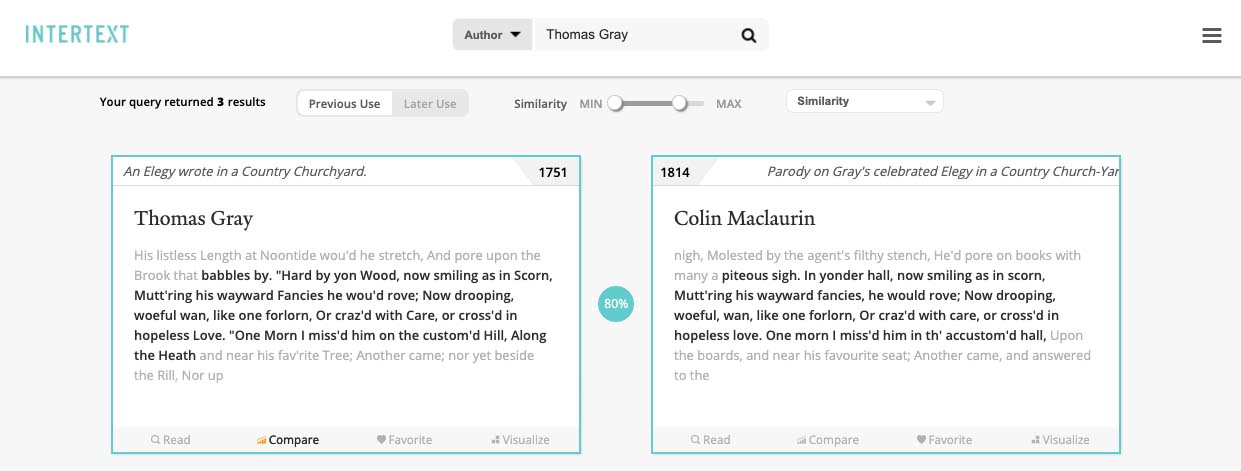 The “Compare” feature on the Intertext web viewer (version 0.1.0), with a side-by-side comparison of two passages.
The “Compare” feature on the Intertext web viewer (version 0.1.0), with a side-by-side comparison of two passages.
The “Visualize” feature divides a text into color-coded segments. These can be shaded and organized to reflect 1) the frequency with which these segments are reused, 2) their level of similarity to a passage in another work, or 3) the years in which similar passages appear.
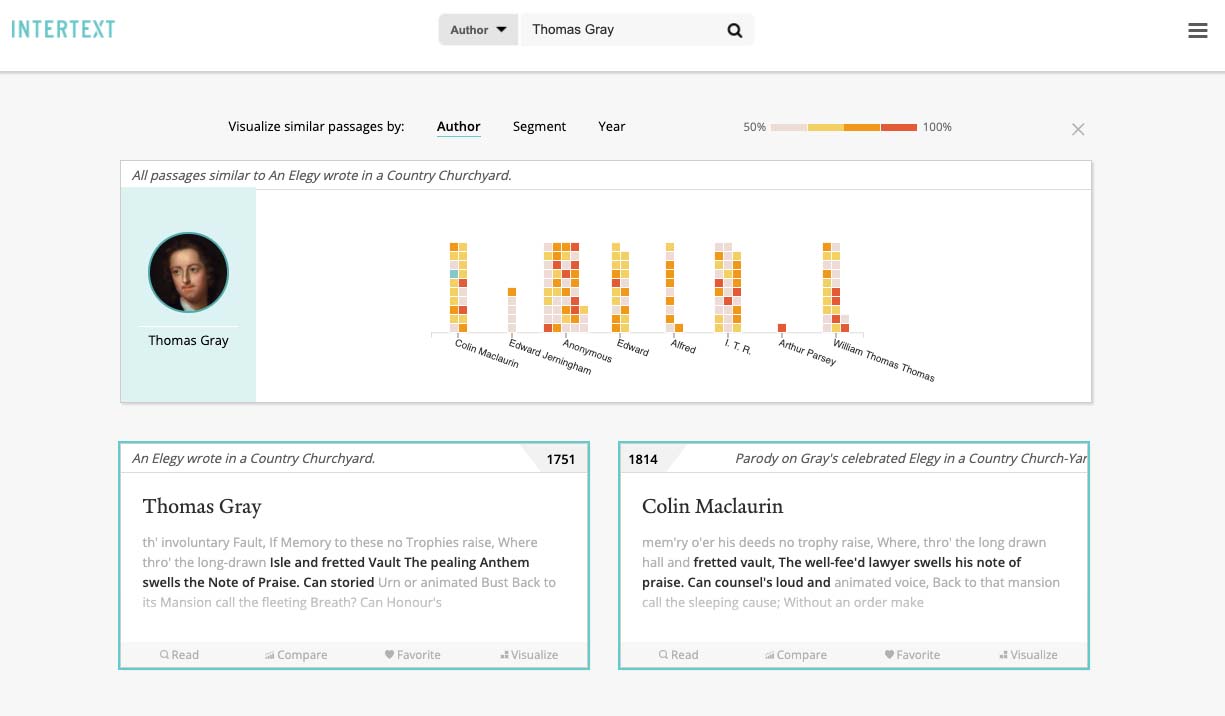 The “Visualize” feature on the Intertext web viewer (version 0.1.0), with color-coded blocks representing similarity to passages in other works.
The “Visualize” feature on the Intertext web viewer (version 0.1.0), with color-coded blocks representing similarity to passages in other works.
Future Developments and Additional Resources
Updates to Intertext will study how modes of distant reading can be built around intertextuality and repetition, and will examine how these practices can allow us to navigate textual corpora. In addition to expanding Intertext’s visualization features, upcoming work will consider the tool’s functionality as a reading environment.
Those studying textual reuse may also wish to consult additional tools alongside Intertext. Possible resources of interest include:
- David Smith’s passim package
- TextPAIR (Pairwise Alignment for Intertextual Relations), a digital humanities package from the University of Chicago’s ARTFL Project
- most especially, Eric Zhu’s datasketch package, which features a useful implementation of the minhash algorithm
An extensive discussion of minhashing can be found in Jure Leskovec, Anand Rajaraman, and Jeff Ullman’s Mining of Massive Datasets, chapter 3: “Finding Similar Items.”
To use Intertext with your own data set, or to explore sample data, please visit the DHLab’s GitHub repository.